<keras.src.callbacks.history.History at 0x3217e1ca0>
lenet.evaluate(x_test, y_test, verbose=0)
[0.10733101516962051, 0.9675999879837036]
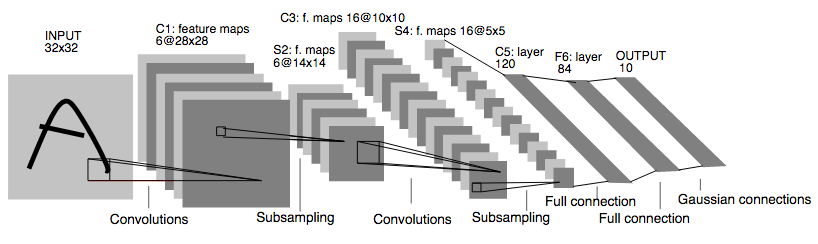
Aunque LeNet fue definido inicialmente usando tanh o sigmoid, esas funciones de activación ahora se usan muy poco. Ambas se saturan con valores muy pequeños o muy grandes, lo que hace que su gradiente sea casi nulo.
Actualmente, la mayoría de las redes utilizan ReLU como función de activación en las capas ocultas, o alguna de sus variantes (https://keras.io/layers/advanced-activations/).
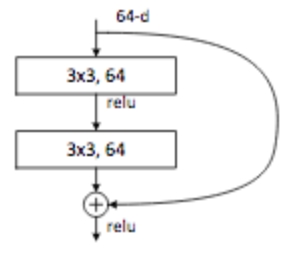
Los modelos ResNet (Residual Networks) fueron introducidos por He et al. en 2015 (paper url). Ellos descubrieron que añadir más capas mejoraba el rendimiento, pero resultaba difícil retropropagar los gradientes hasta las primeras capas.
Un truco para permitir que los gradientes fluyan más fácilmente es utilizar conexiones de cortocircuito (shortcut connections) que dejan el tensor de entrada sin modificar (también conocidas como residuales).
resnet archi
Ejemplo usando la API orientada a objetos:
class MyModel(Model):def__init__(self):self.classifier = Dense(10, activation="softmax")def call(self, inputs):returnself.classifier(inputs)
from tensorflow.keras.layers import Add, Layer, Activationclass ResidualBlock(Layer):def__init__(self, n_filters):super().__init__(name="ResidualBlock")self.conv1 = Conv2D(n_filters, kernel_size=(3, 3), activation="relu", padding="same")self.conv2 = Conv2D(n_filters, kernel_size=(3, 3), padding="same")self.add = Add()self.last_relu = Activation("relu")def call(self, inputs): x =self.conv1(inputs) x =self.conv2(inputs) y =self.add([x, inputs]) y =self.last_relu(y)return yclass MiniResNet(Model):def__init__(self, n_filters):super().__init__()self.conv = Conv2D(n_filters, kernel_size=(5, 5), padding="same")self.block = ResidualBlock(n_filters)self.flatten = Flatten()self.classifier = Dense(10, activation="softmax")def call(self, inputs): x =self.conv(inputs) x =self.block(x) x =self.flatten(x) y =self.classifier(x)return ymini_resnet = MiniResNet(32)# mini_resnet.build((None, *input_shape))mini_resnet.summary()
/Users/aveloz/miniconda3/lib/python3.9/site-packages/keras/src/optimizers/base_optimizer.py:774: UserWarning: Gradients do not exist for variables ['mini_res_net/ResidualBlock/conv2d_5/kernel', 'mini_res_net/ResidualBlock/conv2d_5/bias'] when minimizing the loss. If using `model.compile()`, did you forget to provide a `loss` argument?
warnings.warn(
Batch Normalization no es una arquitectura, es una capa. En el artículo de Ioffe et al. in 2015 (paper url) se señala:
Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learningrates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities. We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs.
El resultado es que las CNNs que se entrenan con BatchNorm convergen más rápido con resultados mejores. Actualmente, todas o casi todas usan alguna forma de BatchNorm. Ver el artículo.
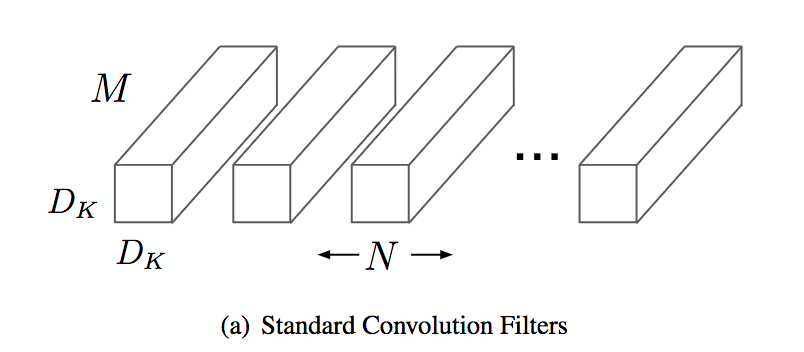
Las CNNs suelen tener muchos parámetros debido a su gran profundidad. Un truco para reducir el número de parámetros con una pérdida mínima en el rendimiento es usar convolución separable.
La convolución estándar tiene muchos parámetros (aunque sigue siendo mucho menos que una capa densa):
Las convoluciones separables consisten en dos tipos de convolución:
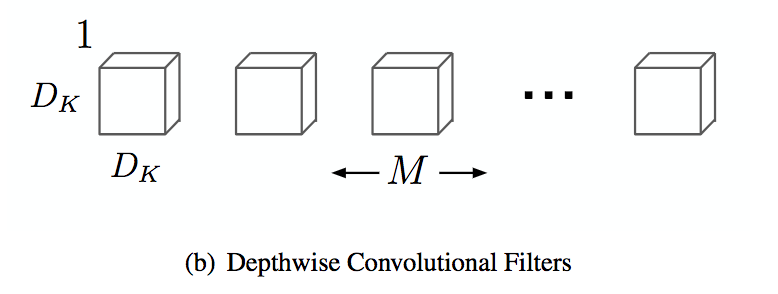
Una convolución depthwise: se crea un único kernel por canal de entrada, por lo que se afecta la información espacial, pero no se comparte información entre canales.
depthwise conv
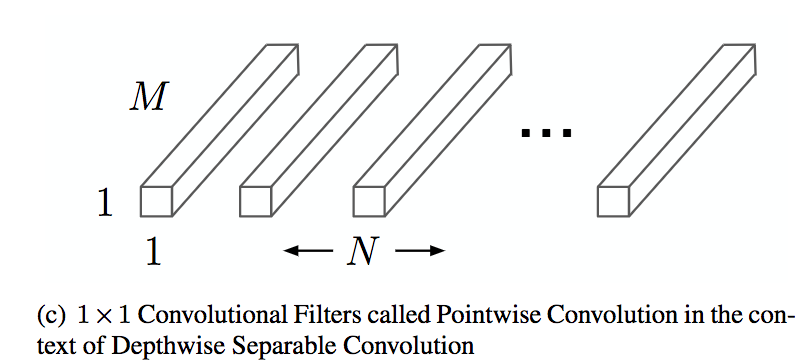
Una convolución pointwise: es una convolución habitual con un kernel de tamaño (1, 1). Aquí, la información espacial no se ve afectada, pero sí se comparte información entre los canales.