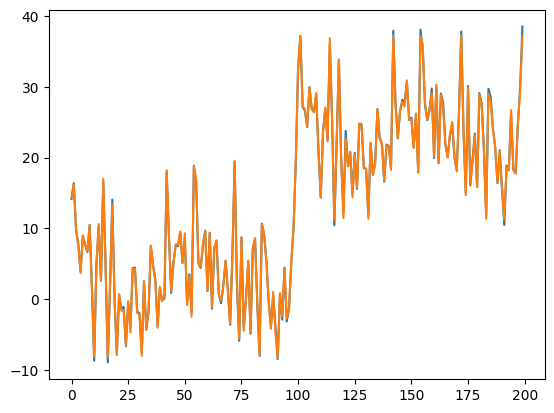
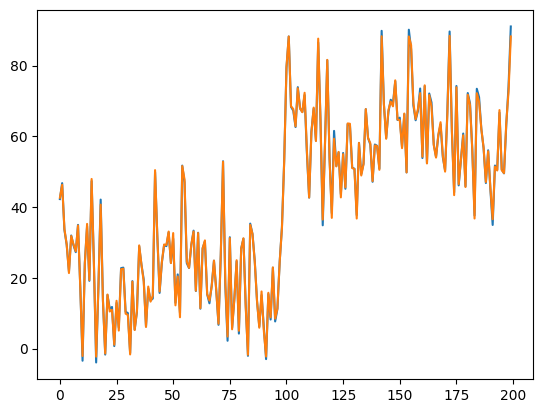
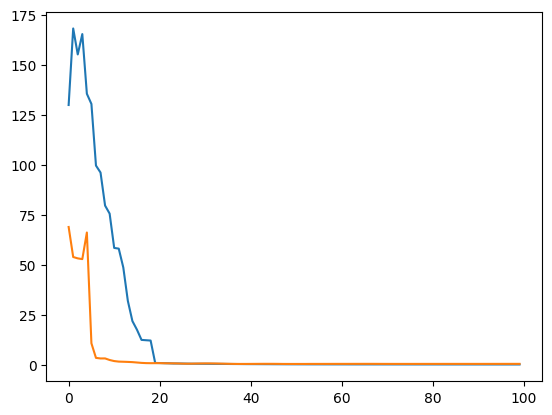
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import os
class MamdaniFISPyTorch(nn.Module):
def __init__(self, n_rules=6, n_points=1000):
super().__init__()
self.n_rules = n_rules
self.n_points = n_points
self.is_fit = False
def initialize_parameters(self, X, Y):
self.x_min = X.min(dim=0).values
self.x_max = X.max(dim=0).values
self.y_min = Y.min(dim=0).values
self.y_max = Y.max(dim=0).values
self.x_ = torch.zeros(self.n_points, self.input_dim)
self.y_ = torch.zeros(self.n_points, self.output_dim)
for idx_dim in range(self.input_dim):
self.x_[:, idx_dim] = torch.linspace(self.x_min[idx_dim], self.x_max[idx_dim], self.n_points)
for idx_dim in range(self.output_dim):
self.y_[:, idx_dim] = torch.linspace(self.y_min[idx_dim], self.y_max[idx_dim], self.n_points)
delta_x = (self.x_max - self.x_min) / (self.n_rules - 1)
sigma_x = delta_x / (2 * np.sqrt(2 * np.log(2)))
for idim in range(self.input_dim):
centers = self.x_min[idim] + torch.arange(self.n_rules) * delta_x[idim]
self.p_premises.data[:, idim, 0] = centers
self.p_premises.data[:, idim, 1] = sigma_x[idim]
delta_y = (self.y_max - self.y_min) / (self.n_rules - 1)
sigma_y = delta_y / (2 * np.sqrt(2 * np.log(2)))
for idim in range(self.output_dim):
centers = self.y_min[idim] + torch.arange(self.n_rules) * delta_y[idim]
self.p_consequent.data[:, idim, 0] = centers
self.p_consequent.data[:, idim, 1] = sigma_y[idim]
def compute_membership_values(self, x, parameters):
n_samples = x.shape[0]
x_rep = x.unsqueeze(1).repeat(1, self.n_rules, 1)
centers = parameters[:,:,0].unsqueeze(0).repeat(n_samples, 1, 1)
spreads = parameters[:,:,1].unsqueeze(0).repeat(n_samples, 1, 1)
mv = torch.exp(-((x_rep - centers) ** 2) \
/ (2 * spreads ** 2))
mv = torch.where(mv < 1e-3, torch.tensor(0.0, device=mv.device, dtype=mv.dtype), mv)
return mv
def forward(self, X):
if not self.is_fit:
raise RuntimeError("Model not fit. Call fit() first.")
if not isinstance(X, torch.Tensor):
X = torch.tensor(X, dtype=torch.float32)
else:
X = X.detach().clone()
if X.dim() == 1:
X = X.unsqueeze(1)
n_samples = X.shape[0]
mv_inputs = self.compute_membership_values(X, self.p_premises) # (n_samples, n_rules, n_dims)
mv_outputs = self.compute_membership_values(self.y_, self.p_consequent) # (n_points, n_rules, n_dims)
mv_outputs = mv_outputs.unsqueeze(0).repeat(n_samples, 1, 1, 1) # (n_samples, n_points, n_rules, n_dims)
firing_strengths = mv_inputs.min(dim=2).values # (n_samples, n_rules)
firing_strengths = firing_strengths.unsqueeze(1).unsqueeze(-1).repeat(1, self.n_points, 1, 1) # (n_samples, n_points, n_rules, n_dims)
outputs_rules = torch.min(firing_strengths, mv_outputs) # (n_samples, n_points, n_rules, n_dims)
outputs_aggreg = torch.max(outputs_rules, dim=2).values # (n_samples, n_points, n_dims)
output_defuzz = torch.sum(self.y_.unsqueeze(0).repeat(n_samples, 1, 1) * outputs_aggreg, dim=1) \
/ (torch.sum(outputs_aggreg, dim=1) + torch.finfo(torch.float32).eps)
return output_defuzz
def fit(self, X, Y, lr=0.01, epochs=500, savefigs=False, val_ratio=0.2, random_seed=42, idx_point=None):
torch.manual_seed(random_seed)
if not isinstance(X, torch.Tensor):
X = torch.tensor(X, dtype=torch.float32)
else:
X = X.detach().clone()
if not isinstance(Y, torch.Tensor):
Y = torch.tensor(Y, dtype=torch.float32)
else:
Y = Y.detach().clone()
if X.dim() == 1:
X = X.unsqueeze(1)
if Y.dim() == 1:
Y = Y.unsqueeze(1)
self.input_dim = X.shape[1]
self.output_dim = Y.shape[1]
self.p_premises = nn.Parameter(torch.zeros(self.n_rules, self.input_dim, 2)) # [center, sigma]
self.p_consequent = nn.Parameter(torch.zeros(self.n_rules, self.output_dim, 2)) # [center, sigma]
self.initialize_parameters(X, Y)
self.is_fit = True
optimizer = optim.Adam(self.parameters(), lr=lr)
loss_fn = nn.MSELoss()
train_losses = []
val_losses = []
n_samples = X.shape[0]
idx = torch.randperm(n_samples)
n_val = int(val_ratio * n_samples)
val_idx = idx[:n_val]
train_idx = idx[n_val:]
X_train = X[train_idx]
Y_train = Y[train_idx]
X_val = X[val_idx]
Y_val = Y[val_idx]
if savefigs:
if idx_point is None:
idx_point = 40
os.makedirs('temp', exist_ok=True)
x_point = X_train[idx_point].unsqueeze(0)
y_point = Y_train[idx_point].unsqueeze(0)
print(x_point.shape, y_point.shape)
self.plot_fs(figname='fig-epoch000')
self.plot_fs(figname='fig-point-epoch000', sample_point=(x_point, y_point))
for epoch in range(epochs):
self.train()
optimizer.zero_grad()
y_pred = self.forward(X_train)
loss = loss_fn(y_pred, Y_train)
train_losses.append(loss.item())
loss.backward()
optimizer.step()
# Val loss
self.eval()
with torch.no_grad():
y_pred_val = self.forward(X_val)
val_loss = loss_fn(y_pred_val, Y_val)
val_losses.append(val_loss.item())
if (epoch + 1) % 10 == 0:
print(f"Epoch {epoch+1}/{epochs}, \
Train Loss: {loss.item():.6f}, \
Val Loss: {val_loss.item():.6f}")
if savefigs:
os.makedirs('temp', exist_ok=True)
self.plot_fs(figname=f'fig-epoch{epoch+1}')
self.plot_fs(figname=f'fig-point-epoch{epoch+1}', sample_point=(x_point, y_point))
return train_losses, val_losses
def plot_fs(self, sample_point=None, figname=None, output_dir='temp'):
mv_inputs = self.compute_membership_values(self.x_, self.p_premises) # (n_points, n_rules, n_dims)
mv_outputs = self.compute_membership_values(self.y_, self.p_consequent) # (n_points, n_rules, n_dims)
########################
nrows = self.n_rules
if sample_point is not None:
nrows = self.n_rules+1
x_point, y_point = sample_point
mv_inputs_ = self.compute_membership_values(x_point, self.p_premises) # (n_samples=1, n_rules, n_dims)
mv_outputs_augm = mv_outputs.unsqueeze(0) # (n_samples, n_points, n_rules, n_dims)
firing_strengths = mv_inputs_.min(dim=2).values # (n_samples, n_rules)
firing_strengths = firing_strengths.unsqueeze(1).unsqueeze(-1).repeat(1, self.n_points, 1, 1) # (n_samples, n_points, n_rules, n_dims)
outputs_rules = torch.min(firing_strengths, mv_outputs_augm) # (n_samples, n_points, n_rules, n_dims)
outputs_aggreg = torch.max(outputs_rules, dim=2).values # (n_samples, n_points, n_dims)
output_defuzz = torch.sum(self.y_.unsqueeze(0) * outputs_aggreg, dim=1) \
/ (torch.sum(outputs_aggreg, dim=1) + torch.finfo(torch.float32).eps)
fig, axs = plt.subplots(nrows=nrows,
ncols=self.input_dim+self.output_dim,
figsize=(12, 10))
# inputs
for idx_dim in range(self.input_dim):
for idx_rule in range(self.n_rules):
axs[idx_rule, idx_dim].plot(self.x_[:, idx_dim].numpy(),
mv_inputs[:, idx_rule, idx_dim].detach().numpy())
axs[idx_rule, idx_dim].set_ylim([0, 1])
axs[idx_rule, idx_dim].set_xlim([self.x_min[idx_dim],
self.x_max[idx_dim]])
if sample_point is not None:
axs[idx_rule, idx_dim].axvline(x_point.numpy().ravel()[idx_dim], ymin=0, ymax=1)
axs[idx_rule, idx_dim].axhline(mv_inputs_.detach().numpy()[0, idx_rule, idx_dim],
xmin=self.x_min.numpy()[idx_dim], xmax=self.x_max.numpy()[idx_dim])
# only show y-axis on the first column
if idx_dim == 0:
axs[idx_rule, 0].set_ylabel(f'Rule {idx_rule+1}')
else:
axs[idx_rule, idx_dim].set_yticklabels([])
# # only show x-axis on the last row
# if idx_rule != self.n_rules - 1:
# axs[idx_rule, idx_dim].set_xticklabels([])
# only show x-axis on the first row
if idx_rule == 0:
axs[idx_rule, idx_dim].xaxis.set_ticks_position('top')
else:
axs[idx_rule, idx_dim].set_xticklabels([])
axs[0, idx_dim].set_title(f'$x_{idx_dim+1}$')
# outputs
for idx_dim in range(self.output_dim):
for idx_rule in range(self.n_rules):
axs[idx_rule, self.input_dim + idx_dim].plot(self.y_[:, idx_dim].numpy(),
mv_outputs[:, idx_rule, idx_dim].detach().numpy())
if sample_point is not None:
axs[idx_rule, self.input_dim + idx_dim].plot(self.y_[:, idx_dim].numpy(),
outputs_rules.detach().numpy()[0, :, idx_rule, idx_dim])
axs[idx_rule, self.input_dim + idx_dim].set_ylim([0, 1])
axs[idx_rule, self.input_dim + idx_dim].set_xlim(
[self.y_min[idx_dim], self.y_max[idx_dim]])
if idx_rule == 0:
axs[idx_rule, self.input_dim + idx_dim].xaxis.set_ticks_position('top')
axs[idx_rule, self.input_dim + idx_dim].set_title(f'$y_{idx_dim+1}$')
else:
axs[idx_rule, self.input_dim + idx_dim].set_xticklabels([])
axs[idx_rule, self.input_dim + idx_dim].set_yticklabels([])
if sample_point is not None:
# show the aggregated fuzzy set
for idx_dim in range(self.input_dim):
axs[-1, idx_dim].axis('off')
for idx_dim in range(self.output_dim):
axs[-1, self.input_dim + idx_dim].plot(self.y_[:, idx_dim].numpy(),
outputs_aggreg.detach().numpy()[0, :, idx_dim])
axs[-1, self.input_dim + idx_dim].set_ylim([0, 1])
axs[-1, self.input_dim + idx_dim].set_xlim([self.y_min[idx_dim], self.y_max[idx_dim]])
if idx_dim == 0:
axs[-1, self.input_dim + idx_dim].set_ylabel('Output')
else:
axs[-1, self.input_dim + idx_dim].set_yticklabels([])
axs[-1, self.input_dim + idx_dim].axvline(output_defuzz.detach().numpy().ravel()[idx_dim], ymin=0, ymax=1)
axs[-1, self.input_dim + idx_dim].axvline(y_point.numpy().ravel()[idx_dim], ymin=0, ymax=1, color='red')
plt.tight_layout(pad=0.05, w_pad=0.02, h_pad=0.02)
if figname is not None:
plt.savefig(os.path.join(output_dir, f'{figname}.pdf'))
plt.close(fig)
else:
plt.show()